Better DevOps practices for for high performing software teams
Slide 1

Slide 2

Slide 3
Slide 4

Jeremy Meiss Director, DevRel & Community
Slide 5

Slide 6
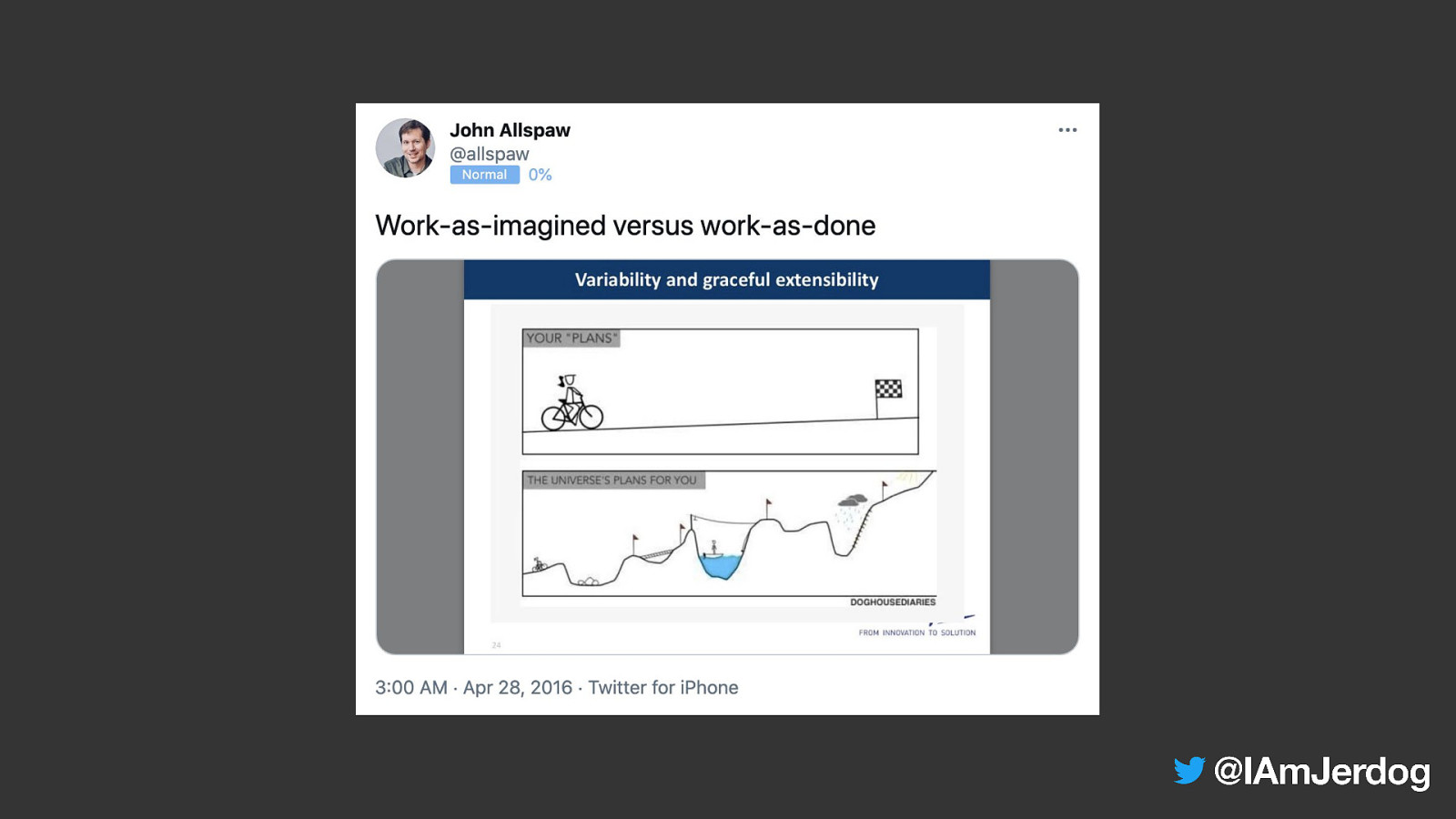
“
Slide 7

performance described vs performance derived
Slide 8
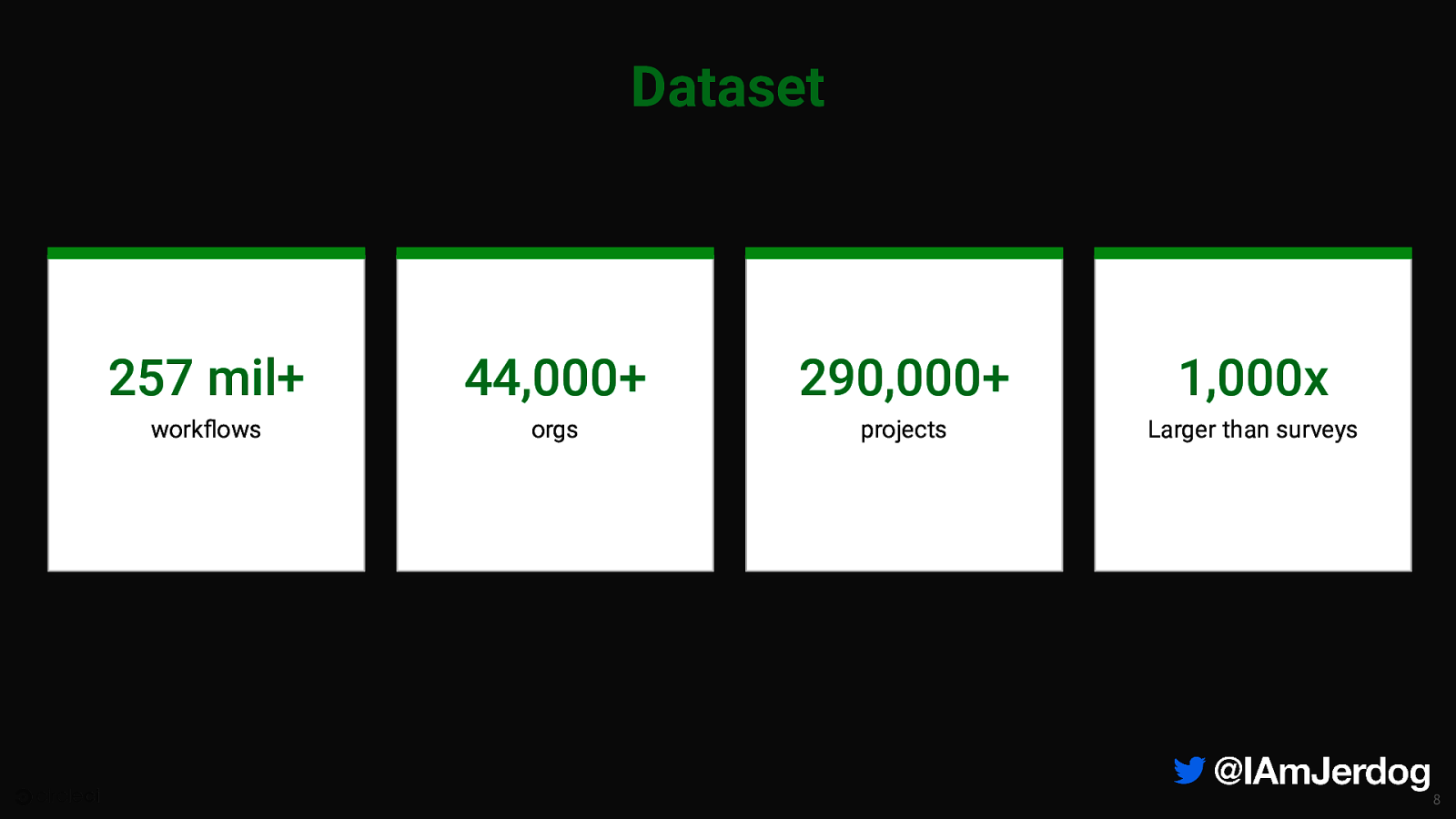
Dataset 257 mil+ 44,000+ 290,000+ 1,000x workflows orgs projects Larger than surveys 8
Slide 9

Image: Risk Culture
Slide 10

Four classic metrics Deployment frequency Lead time to change Change failure rate Recovery from failure time
Slide 11
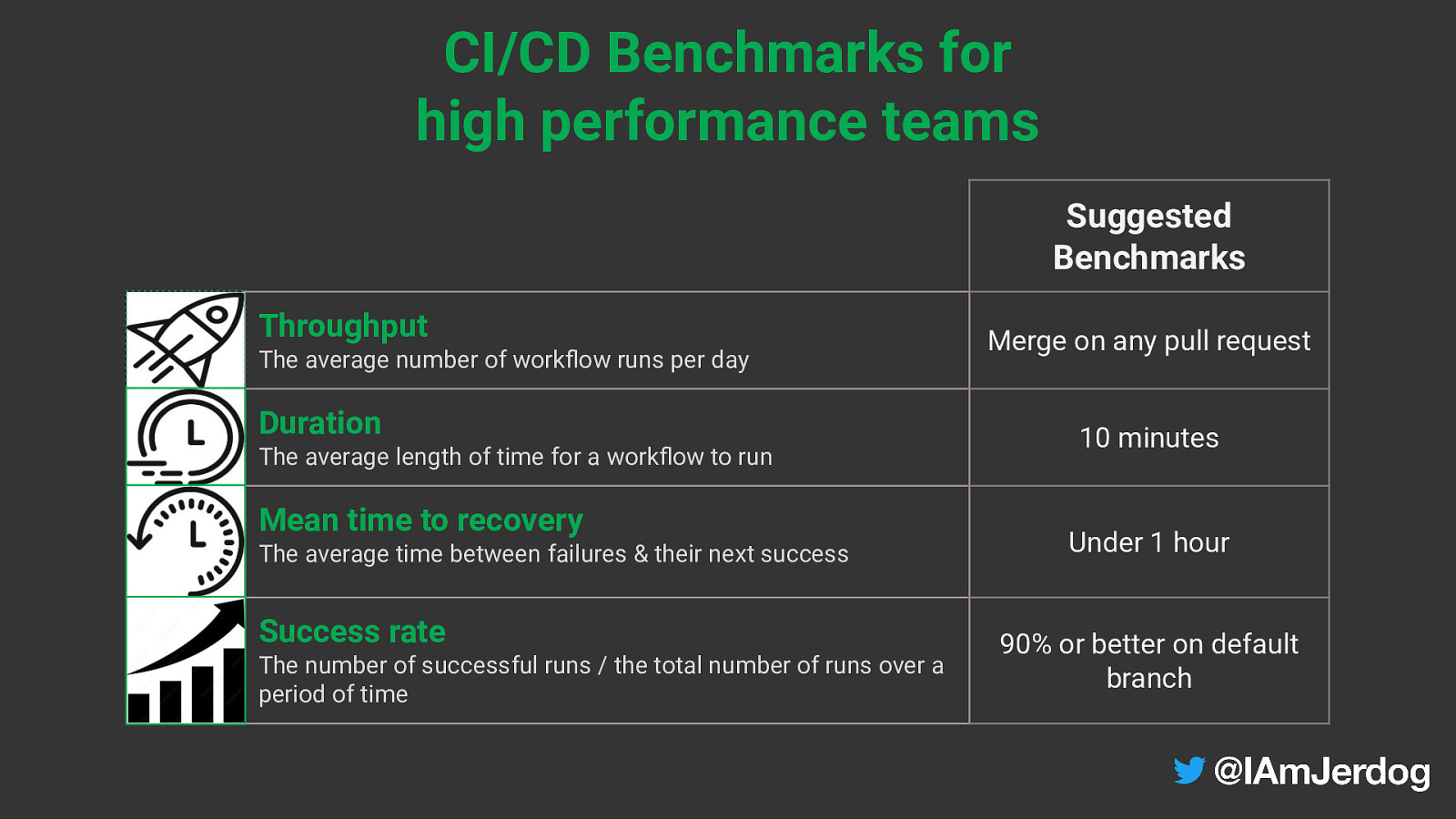
CI/CD Benchmarks for high performance teams Suggested Benchmarks Throughput The average number of workflow runs per day Duration The average length of time for a workflow to run Mean time to recovery The average time between failures & their next success Success rate The number of successful runs / the total number of runs over a period of time Merge on any pull request 10 minutes Under 1 hour 90% or better on default branch
Slide 12

12
Slide 13

The Data
Slide 14

Photo by: Matthew Henry 14
Slide 15

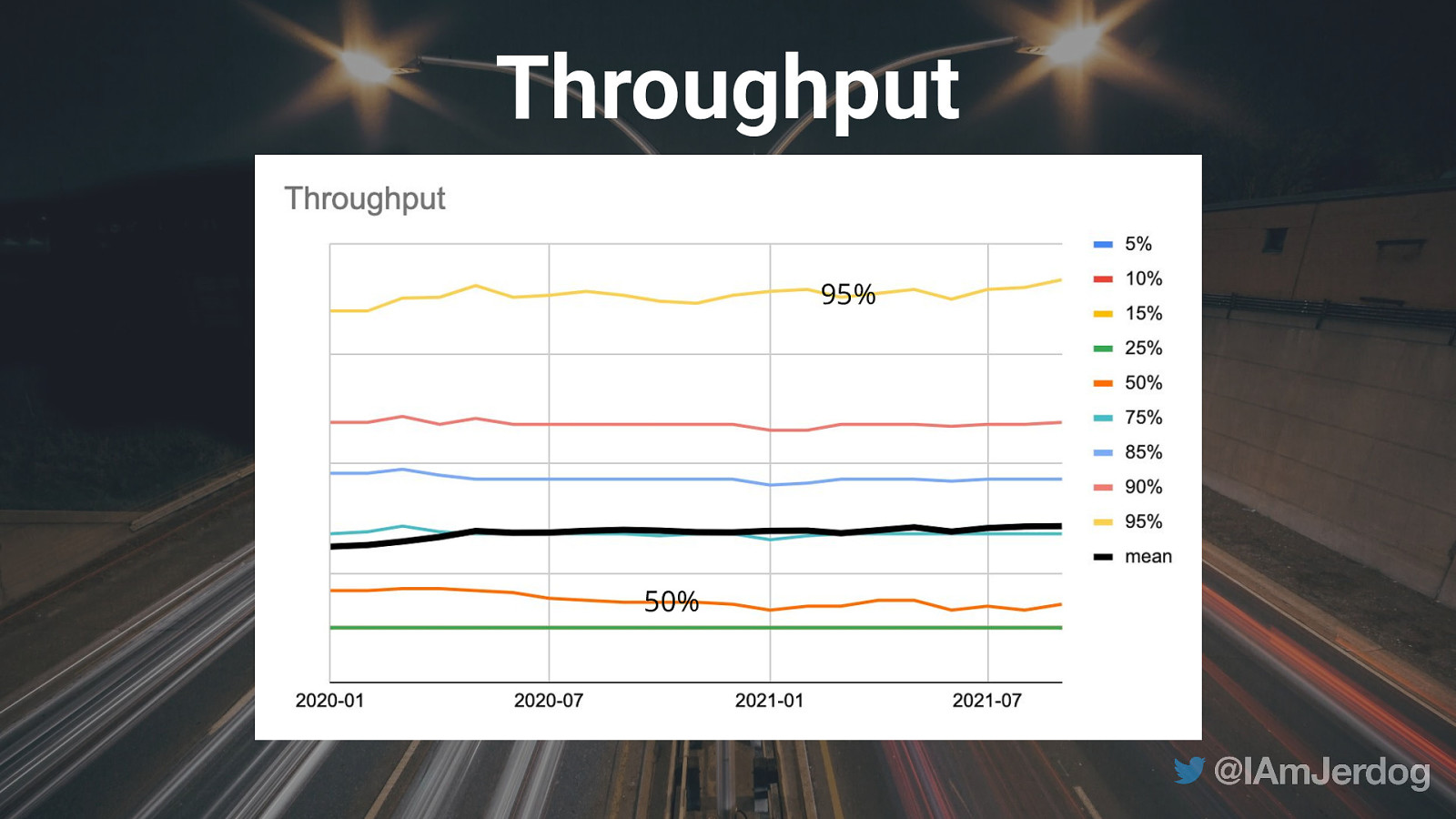
Throughput the average number of workflow runs per day 15
Slide 16
16
Slide 17

Throughput TIP: make smaller commits more often 17
Slide 18
Throughput 95% 50% 50%
Slide 19

95% 50% Image credit: Giphy
Slide 20
Throughput April 2020 20
Slide 21
Throughput April 2020 21
Slide 22

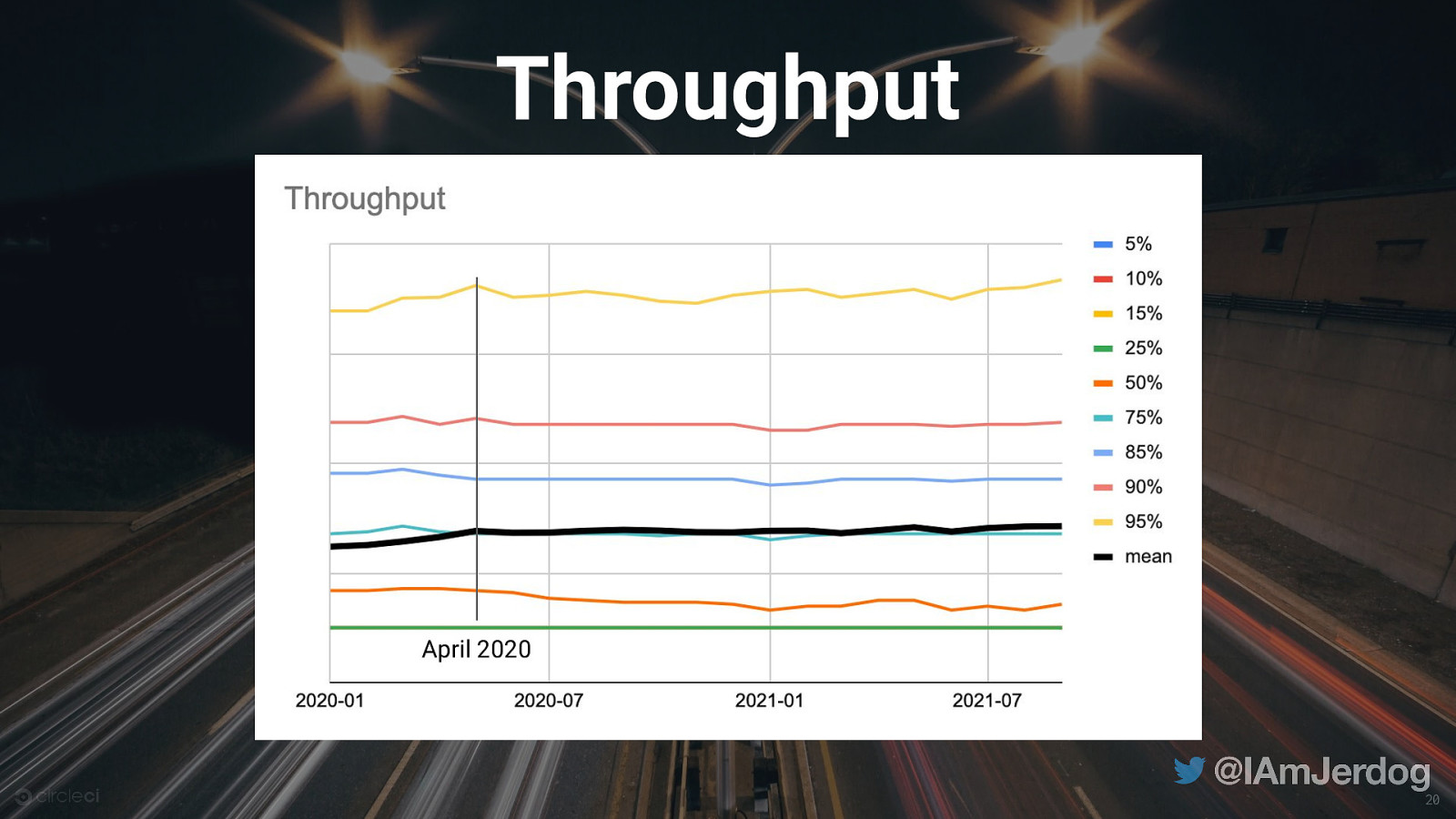
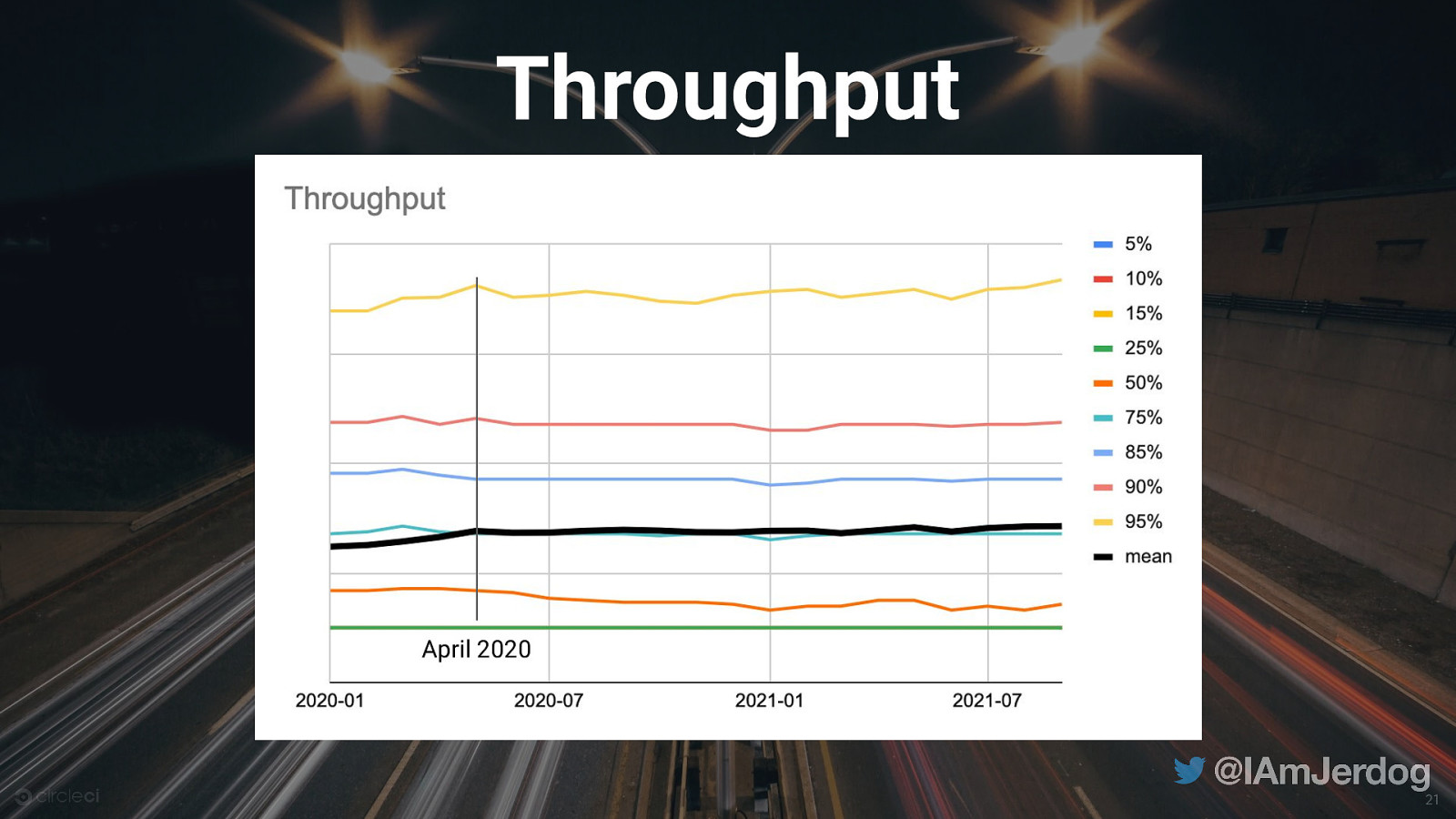
Most teams are not deploying dozens of times per day
Slide 23

High-performing Teams & Throughput ● More valuable for orgs to see changes / progress week-over-week ● Prioritize lean, Agile software development patterns with small, incremental changes 23
Slide 24

Image by Pawan Kolhe from Pixabay
Slide 25

Duration Image by Pawan Kolhe from Pixabay the length of time it takes for a workflow to run 25
Slide 26

Image by Pawan Kolhe from Pixabay 26
Slide 27
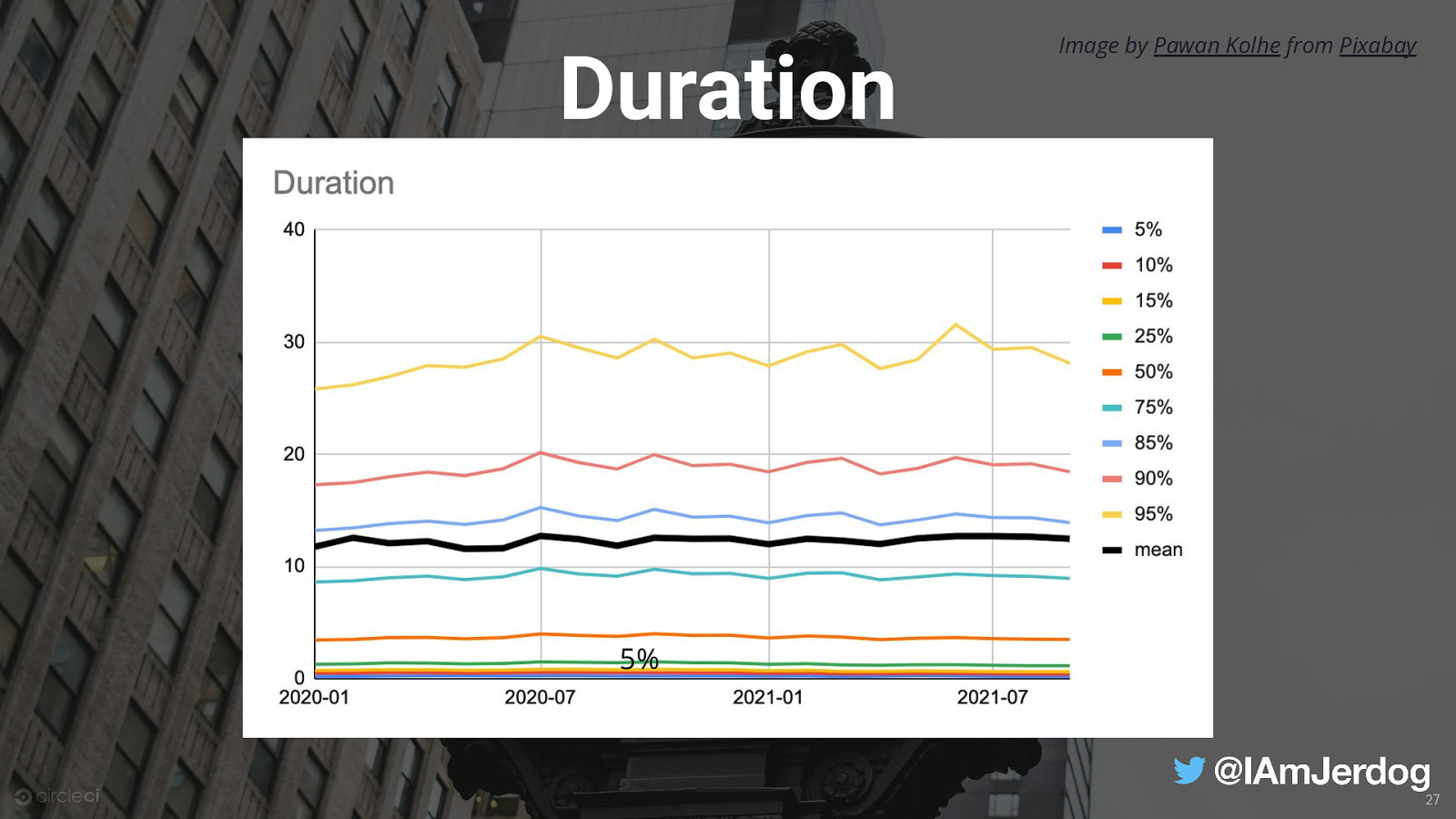
Duration Image by Pawan Kolhe from Pixabay 5% 27
Slide 28
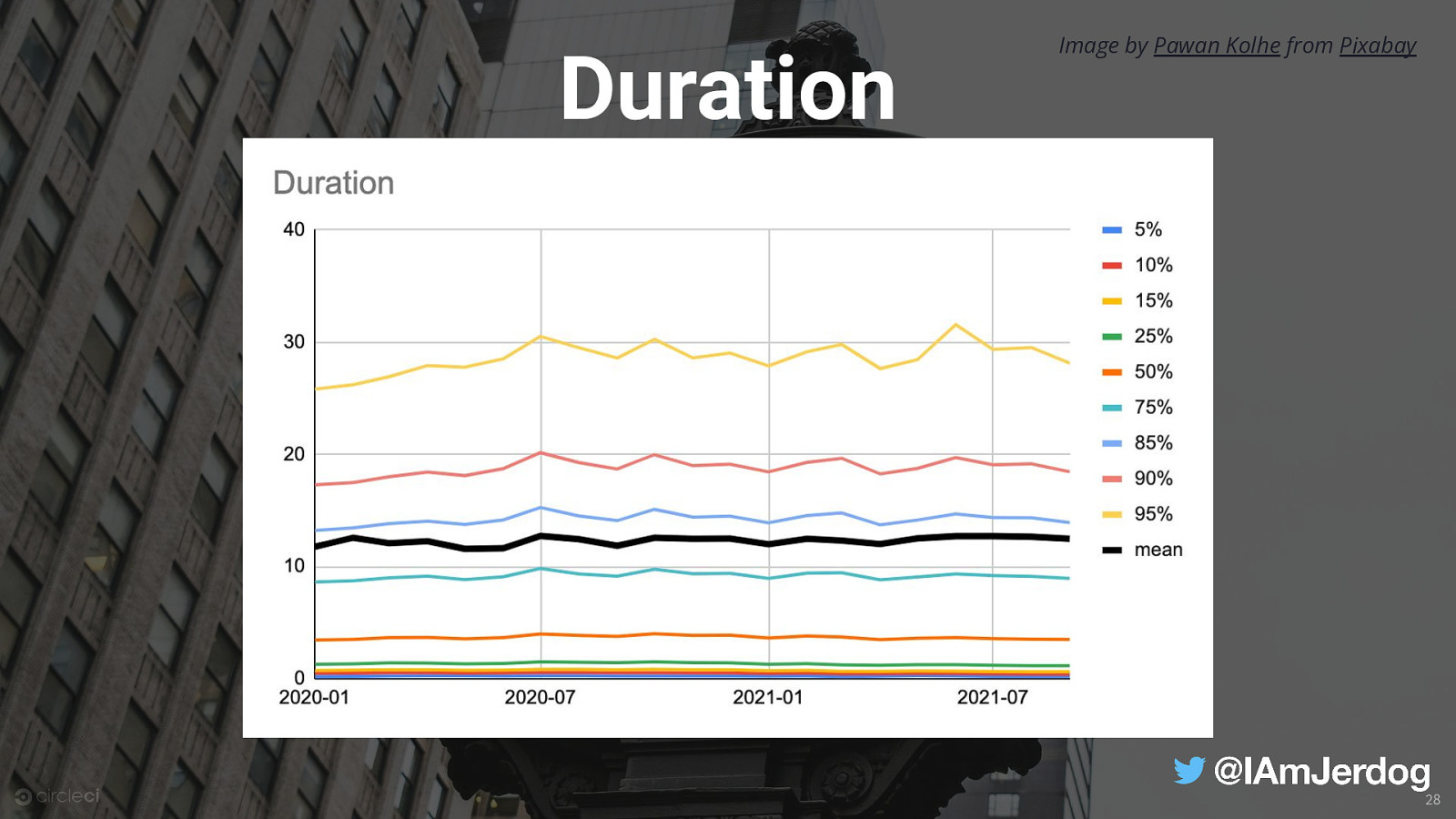
Duration Image by Pawan Kolhe from Pixabay 28
Slide 29
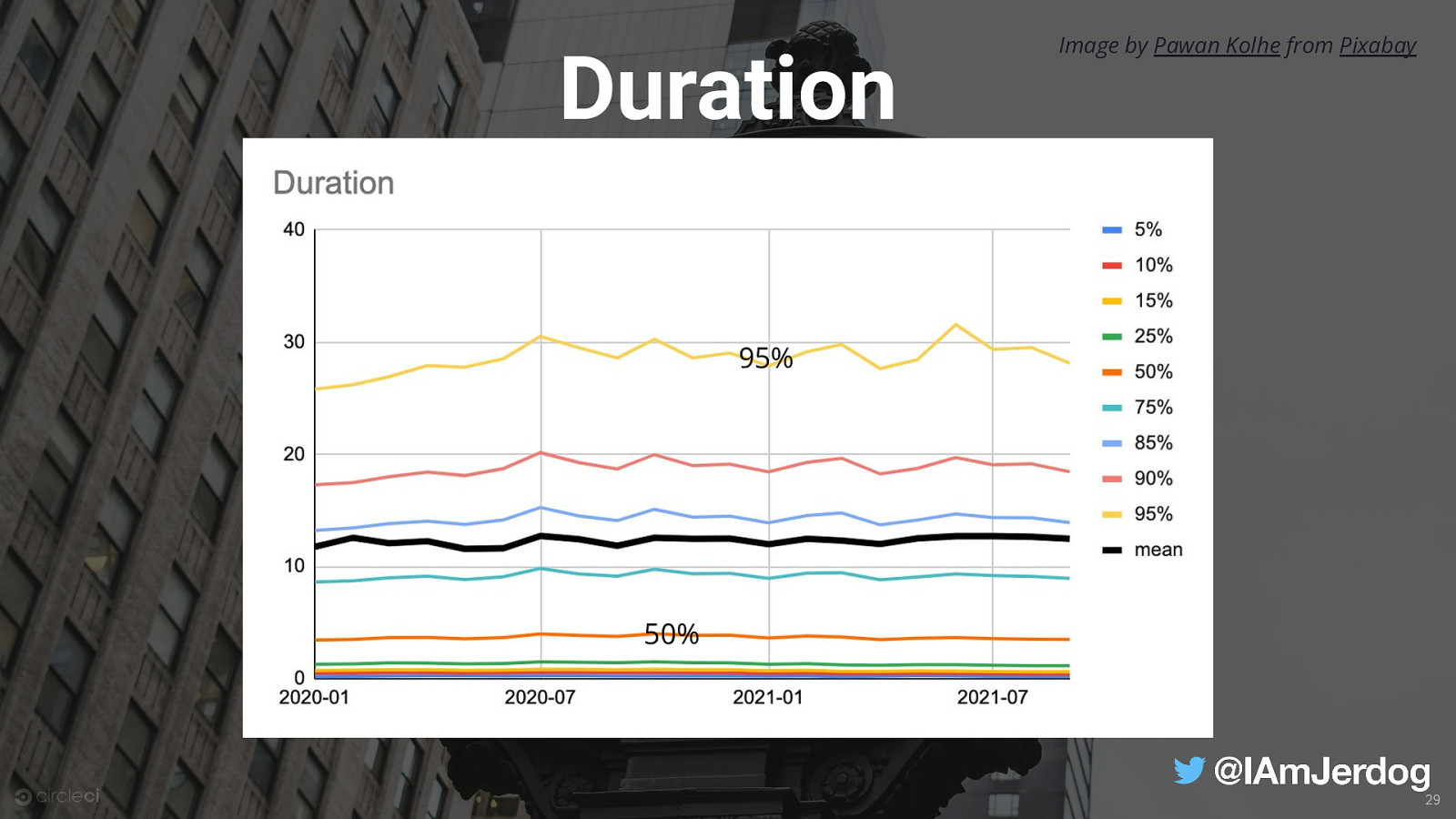
Duration Image by Pawan Kolhe from Pixabay 95% 50% 29
Slide 30
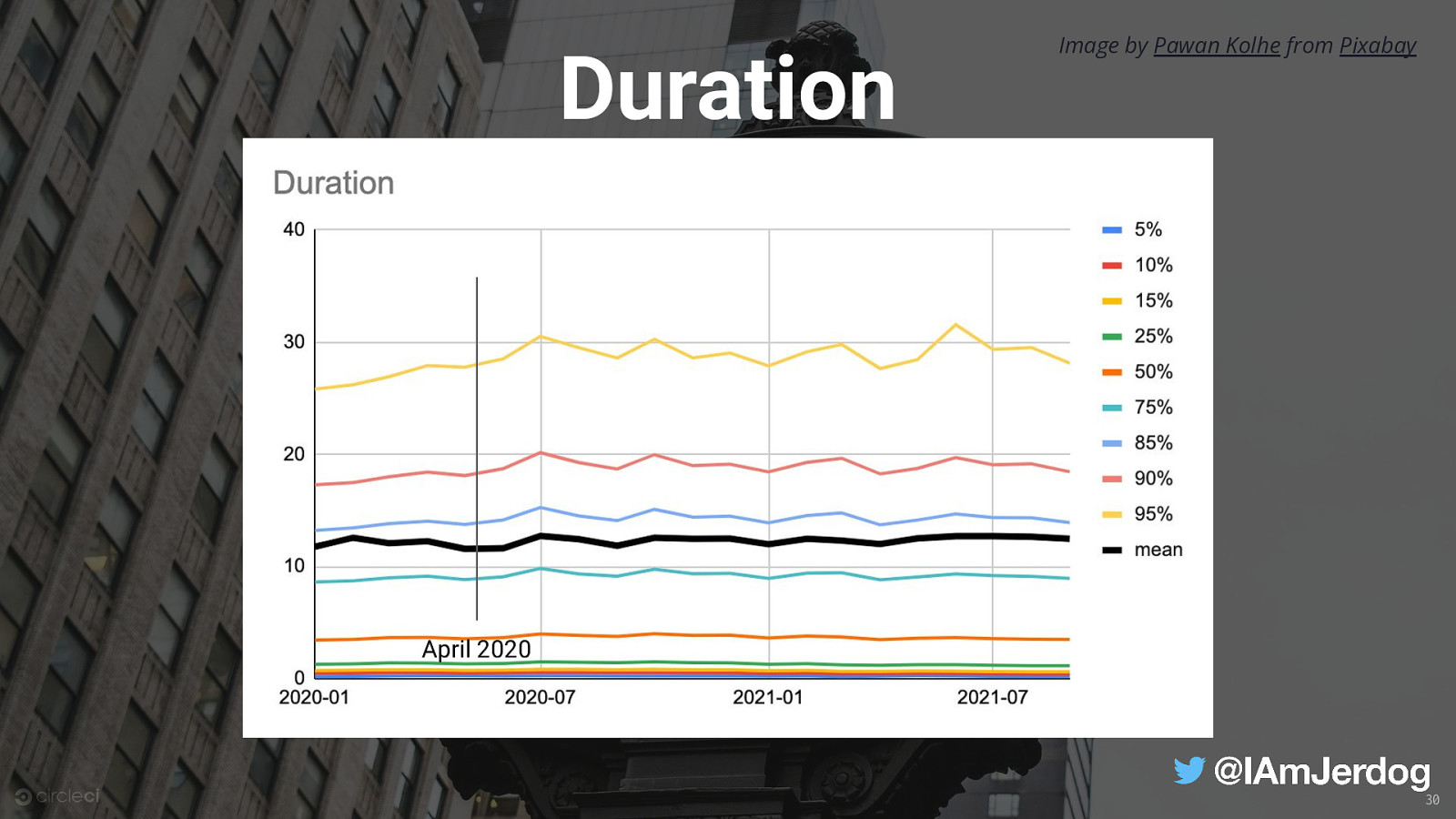
Duration Image by Pawan Kolhe from Pixabay April 2020 30
Slide 31

High-performing Teams & Duration ● ● ● ● Use test splitting to split tests Use Docker images specific for CI Use caching strategies to allow for reuse Use optimal size machine to run workflow 31
Slide 32

Photo by Brett Sayles from Pexels
Slide 33

Mean time to recovery average time between a pipeline’s failure and its next success
Slide 34
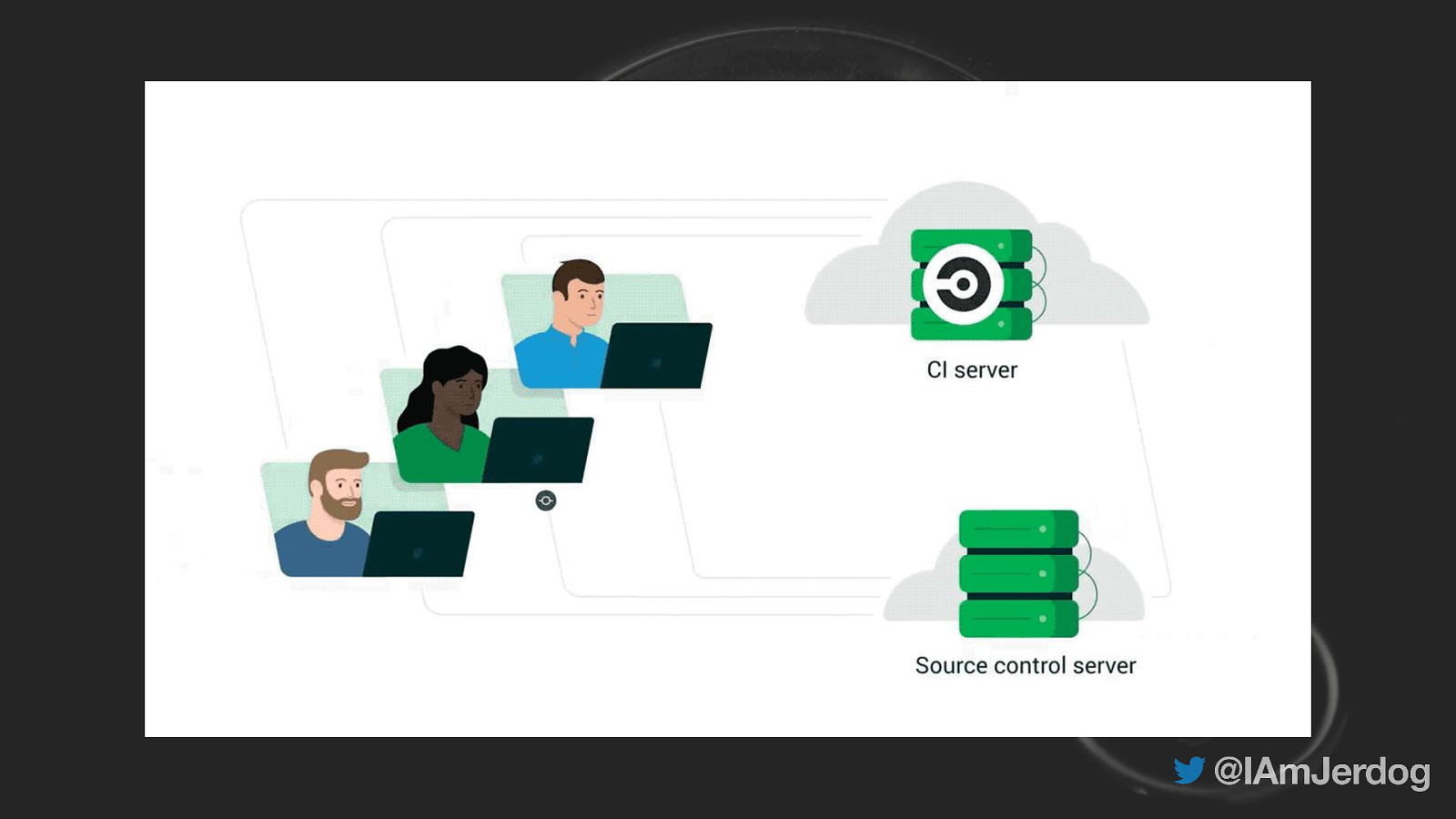
Slide 35

Mean time to recovery shortest MTTR ∝ Duration
Slide 36

“…the most robust — and certainly the fastest — solution to a broken build is to simply revert the offending commit, allowing troubleshooting to happen in a way that doesn’t interfere with the rest of the team. You can’t know whether a new build works or not unless you’re starting from a known good position, which means you should never allow a new build to start on a red build unless it’s explicitly designed to fix it, and it’s hard to imagine a commit more likely to fix a broken build than simply reverting the one that broke it to begin with.” - Brandon Byers, Head of Technology, NA @ Thoughtworks Photo by Brett Sayles from Pexels 36
Slide 37
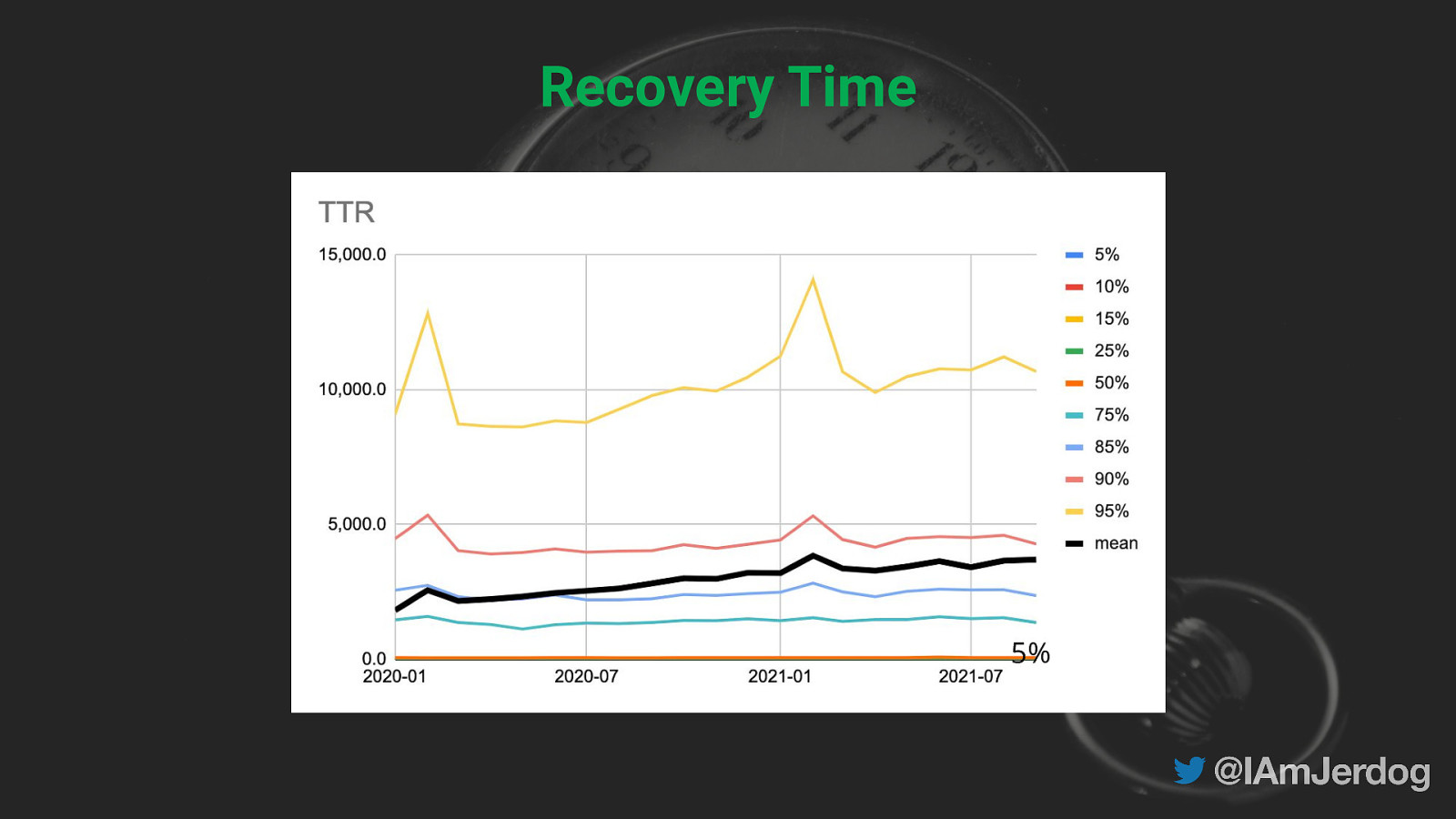
Recovery Time 5%
Slide 38
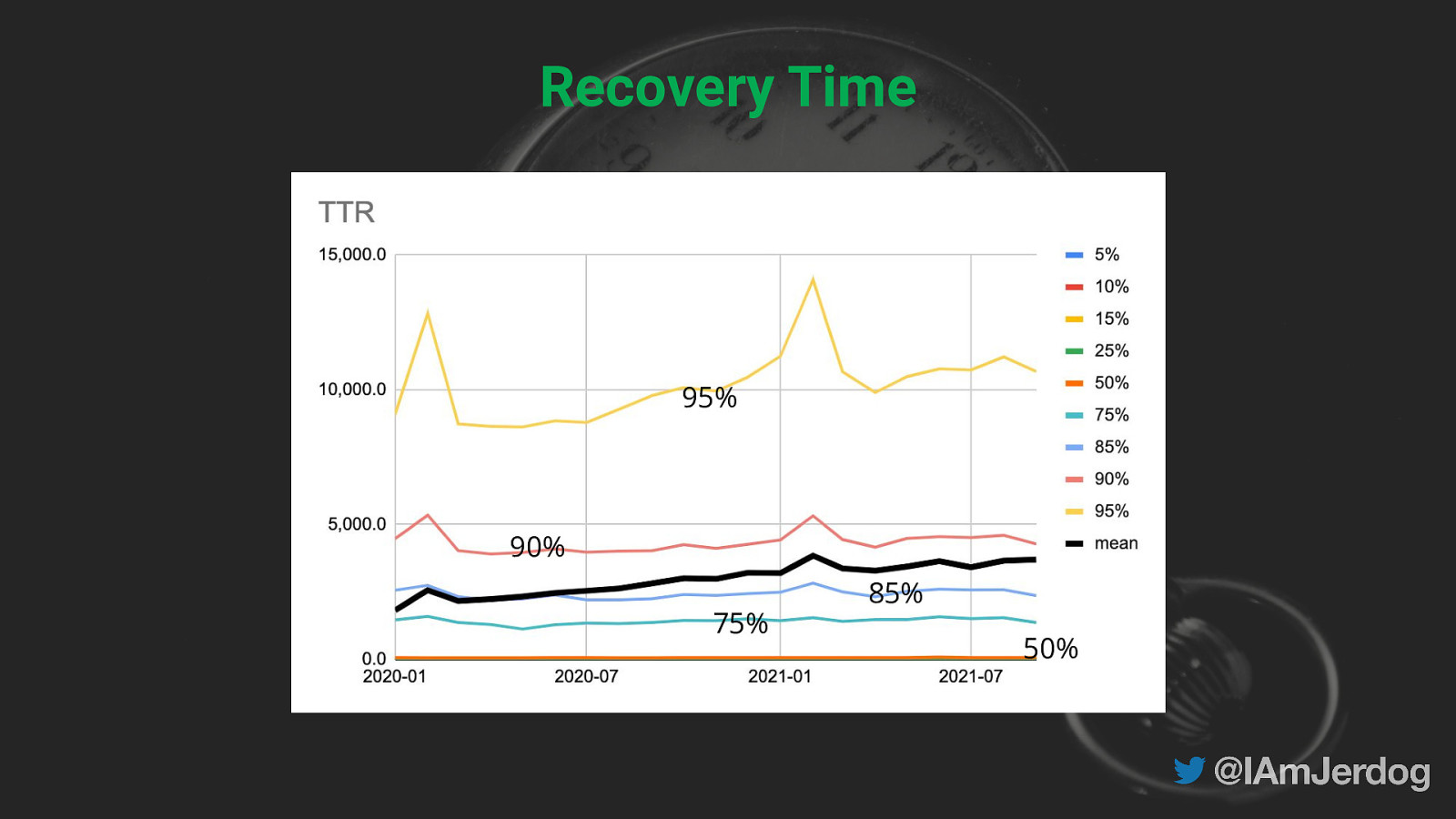
Recovery Time 95% 90% 75% 85% 50%
Slide 39
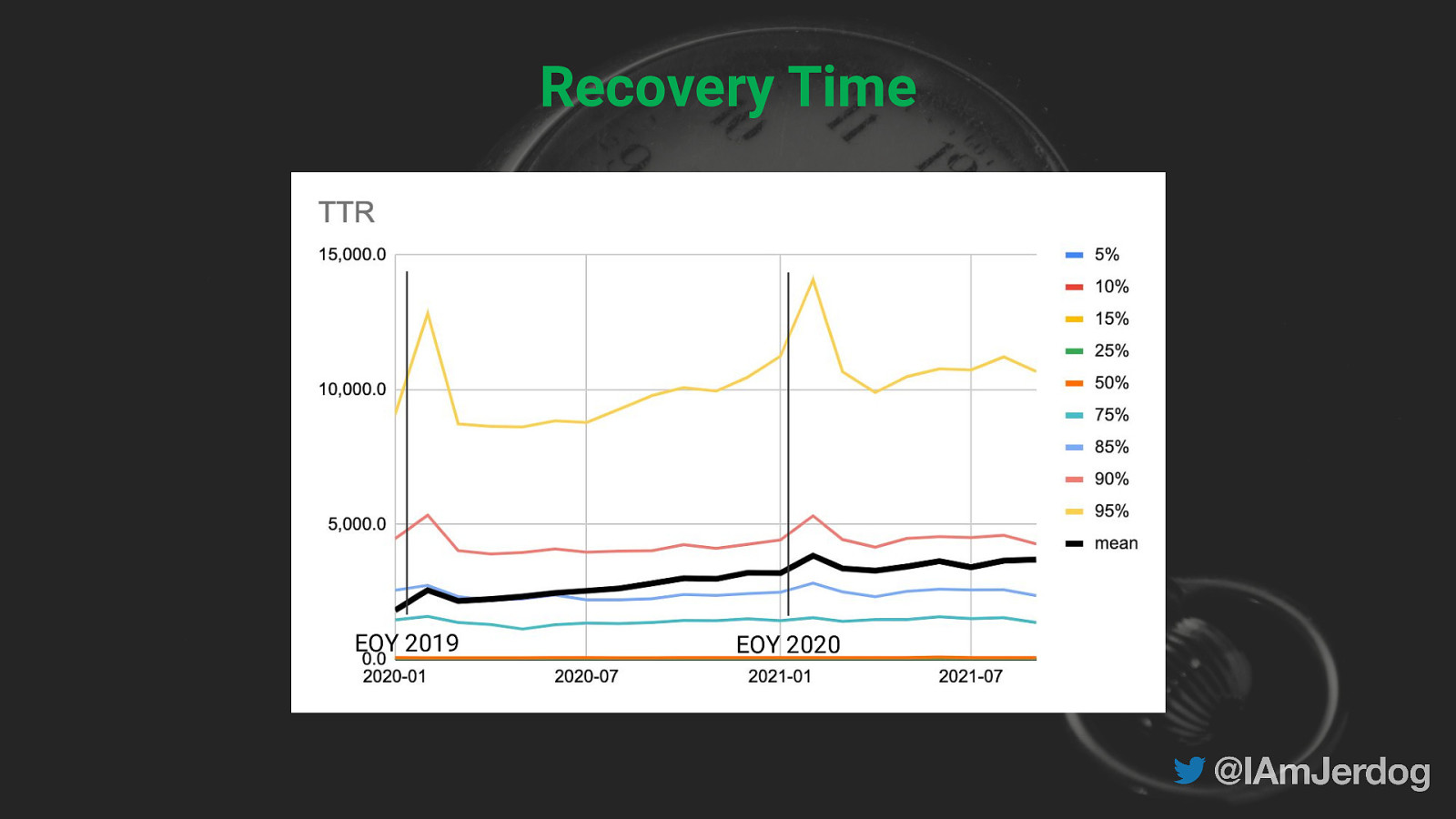
Recovery Time EOY 2019 EOY 2020
Slide 40

High-performing Teams & MTTR ● Duration is the most important factor to optimizing TTR - optimize it first ● Implement tooling for rapid identification and notification of failure ● Write tests to include expert error reporting to quickly identify the problem ● Debug on the remote machine where failure occurs, or at least rich, robust, verbose log output 40
Slide 41

Photo by Lukas from Pexels
Slide 42

Success rate The number of passing runs ÷ total number of runs over a period of time 42
Slide 43
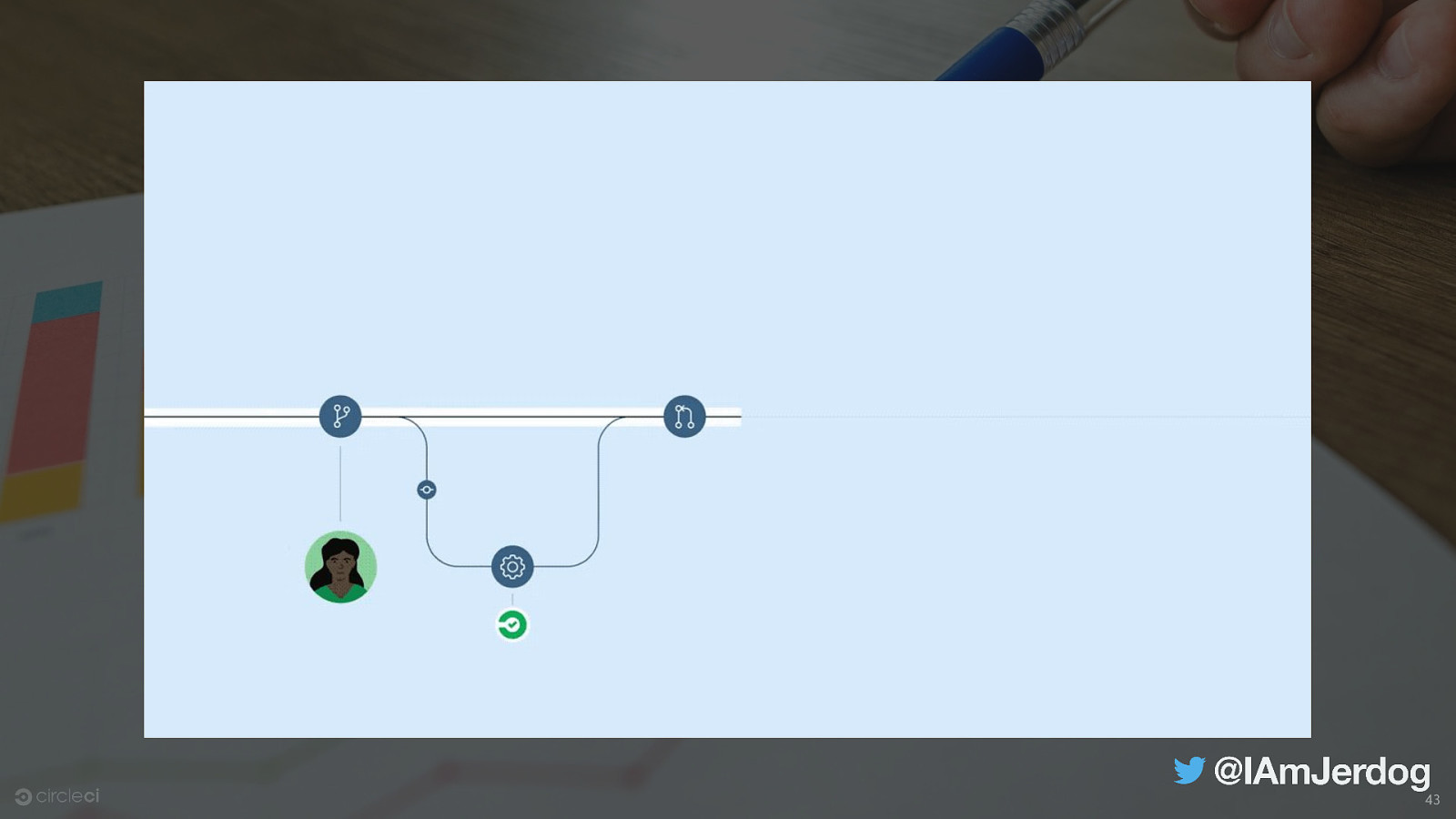
43
Slide 44
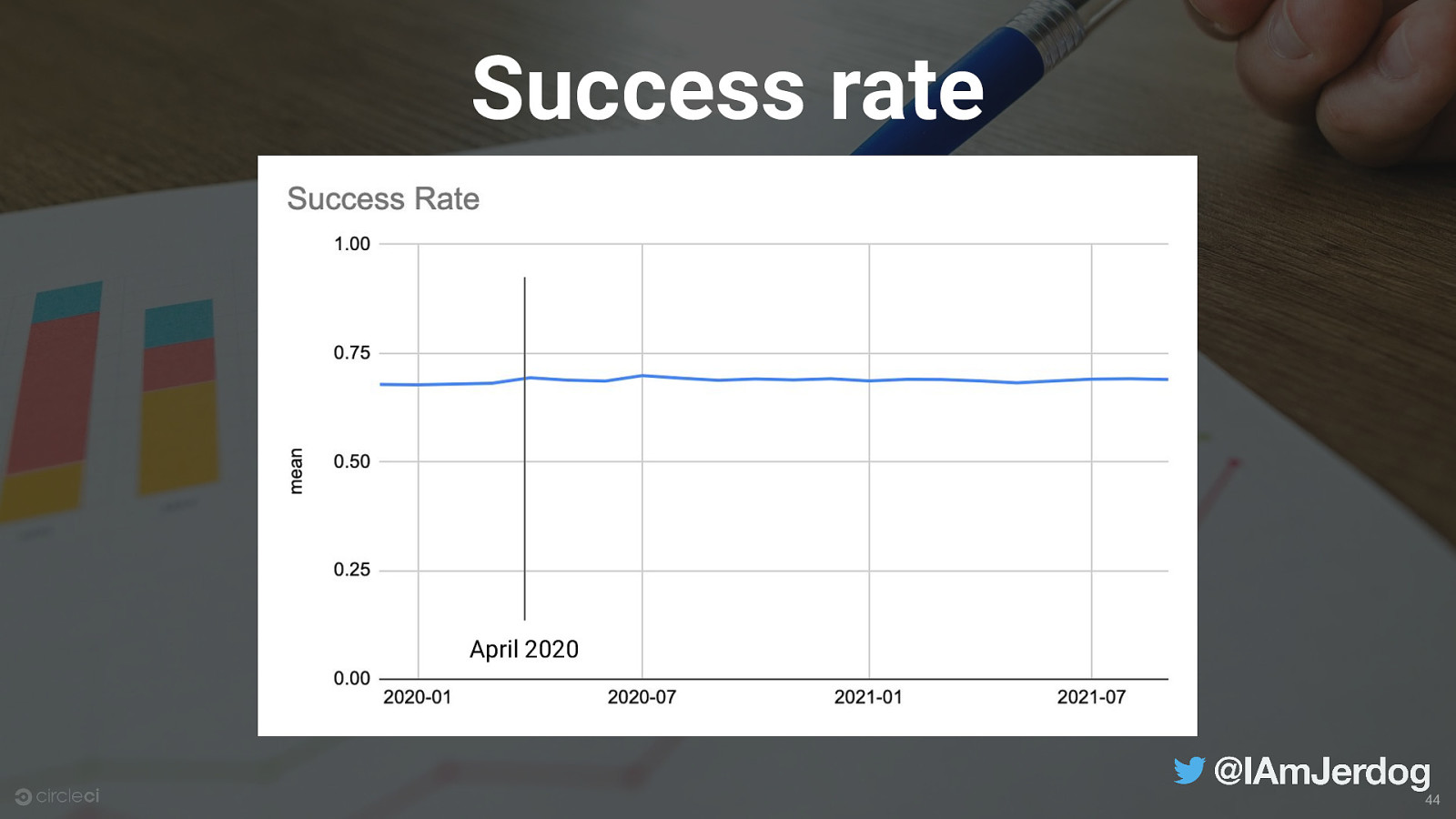
Success rate April 2020 44
Slide 45

Success rate April 2020 45
Slide 46
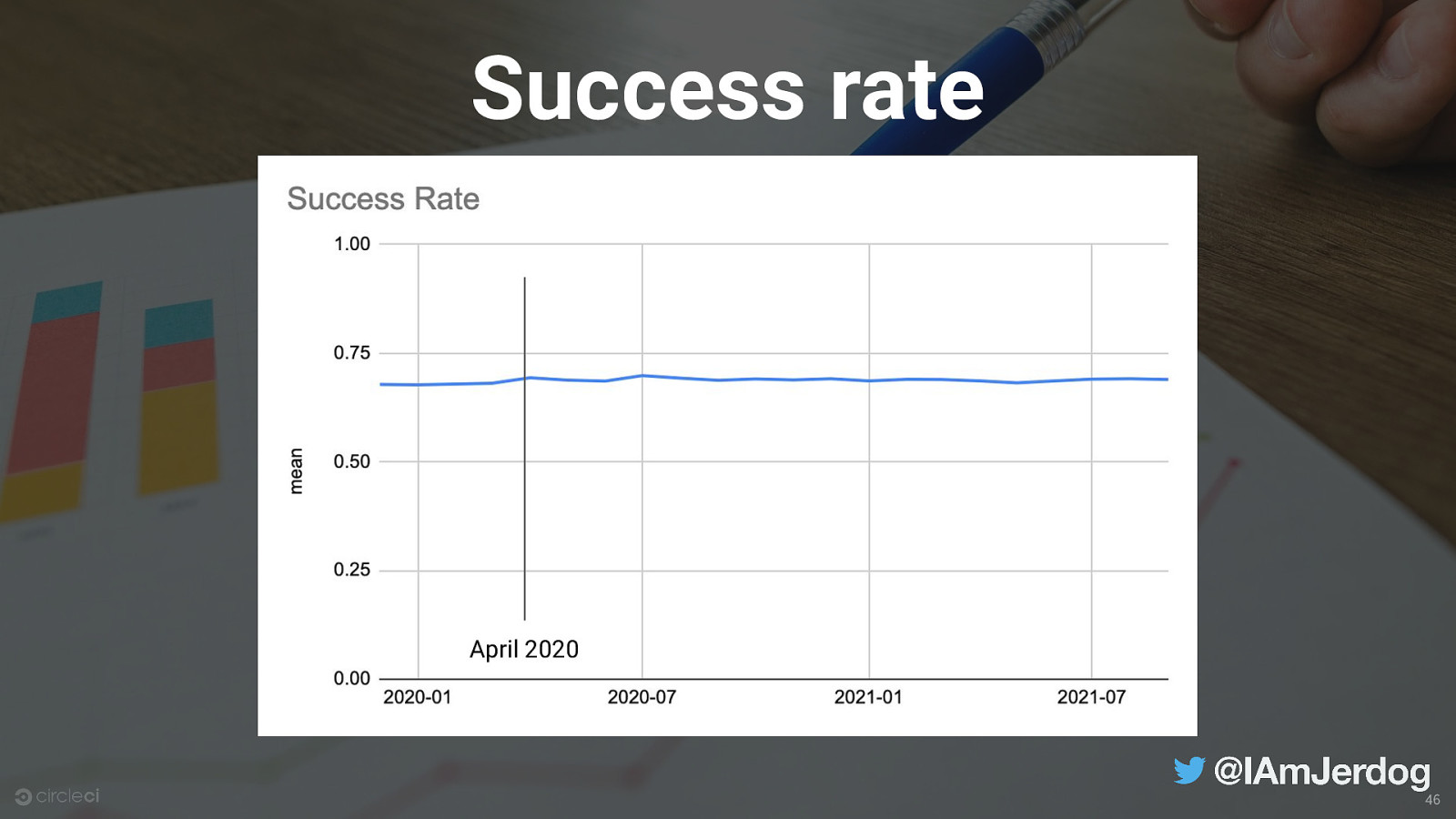
Success rate April 2020 46
Slide 47

Default branches should have high success rates; feature and dev branches should have low success rates
Slide 48

High-performing Teams & Success rate ● Success rate should always be high on the primary branch, feature branches shouldn’t be ● Feature branches should have lower Success rates without negatively affecting the product, but monitor MTTR for signs of insufficient test output 48
Slide 49

So what should a high-performing team look like?
Slide 50
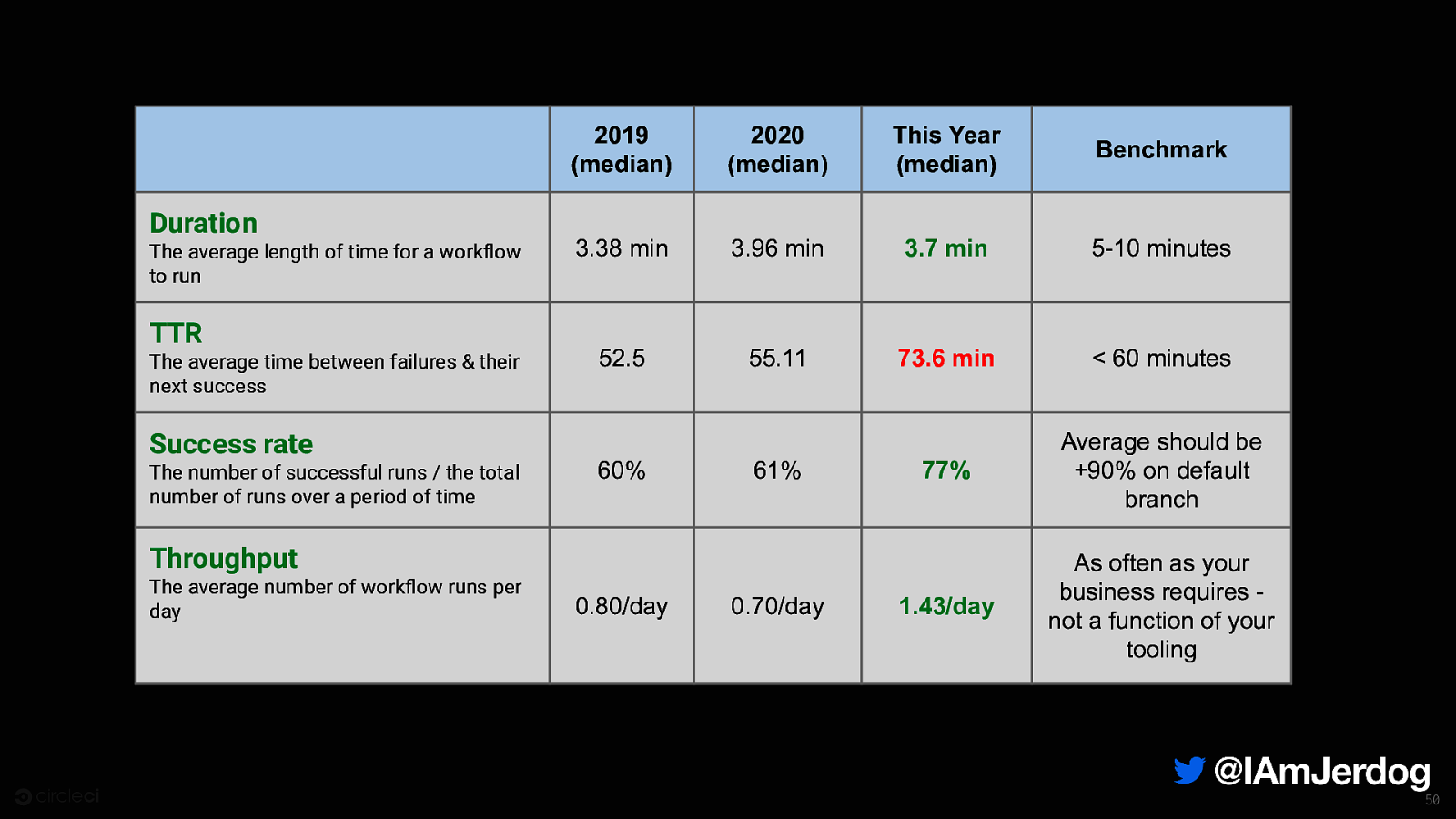
Duration The average length of time for a workflow to run TTR The average time between failures & their next success 2019 (median) 2020 (median) This Year (median) Benchmark 3.38 min 3.96 min 3.7 min 5-10 minutes 52.5 55.11 73.6 min < 60 minutes 77% Average should be +90% on default branch 1.43/day As often as your business requires not a function of your tooling Success rate The number of successful runs / the total number of runs over a period of time 60% 61% Throughput The average number of workflow runs per day 0.80/day 0.70/day 50
Slide 51

51
Slide 52
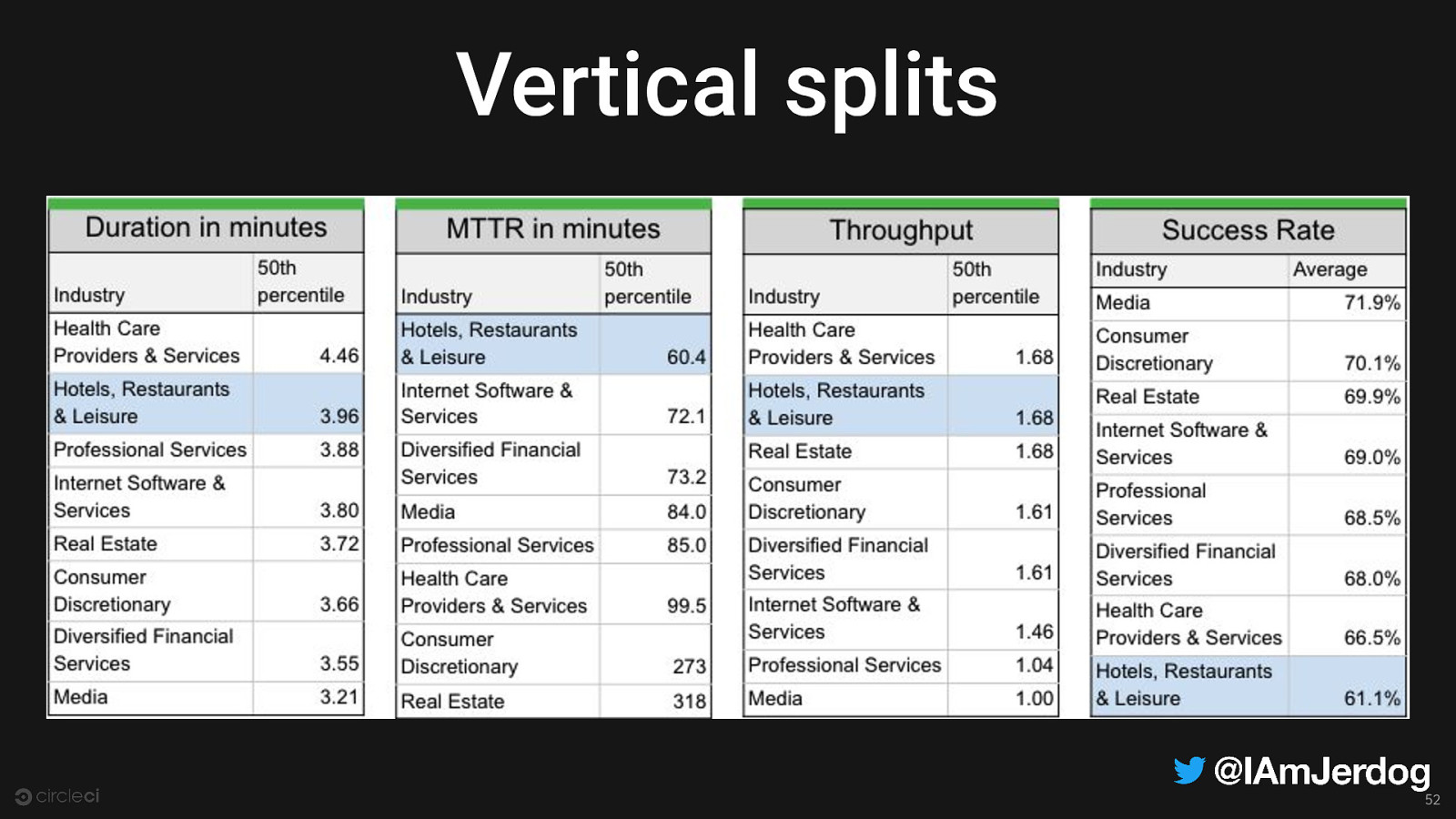
Vertical splits 52
Slide 53
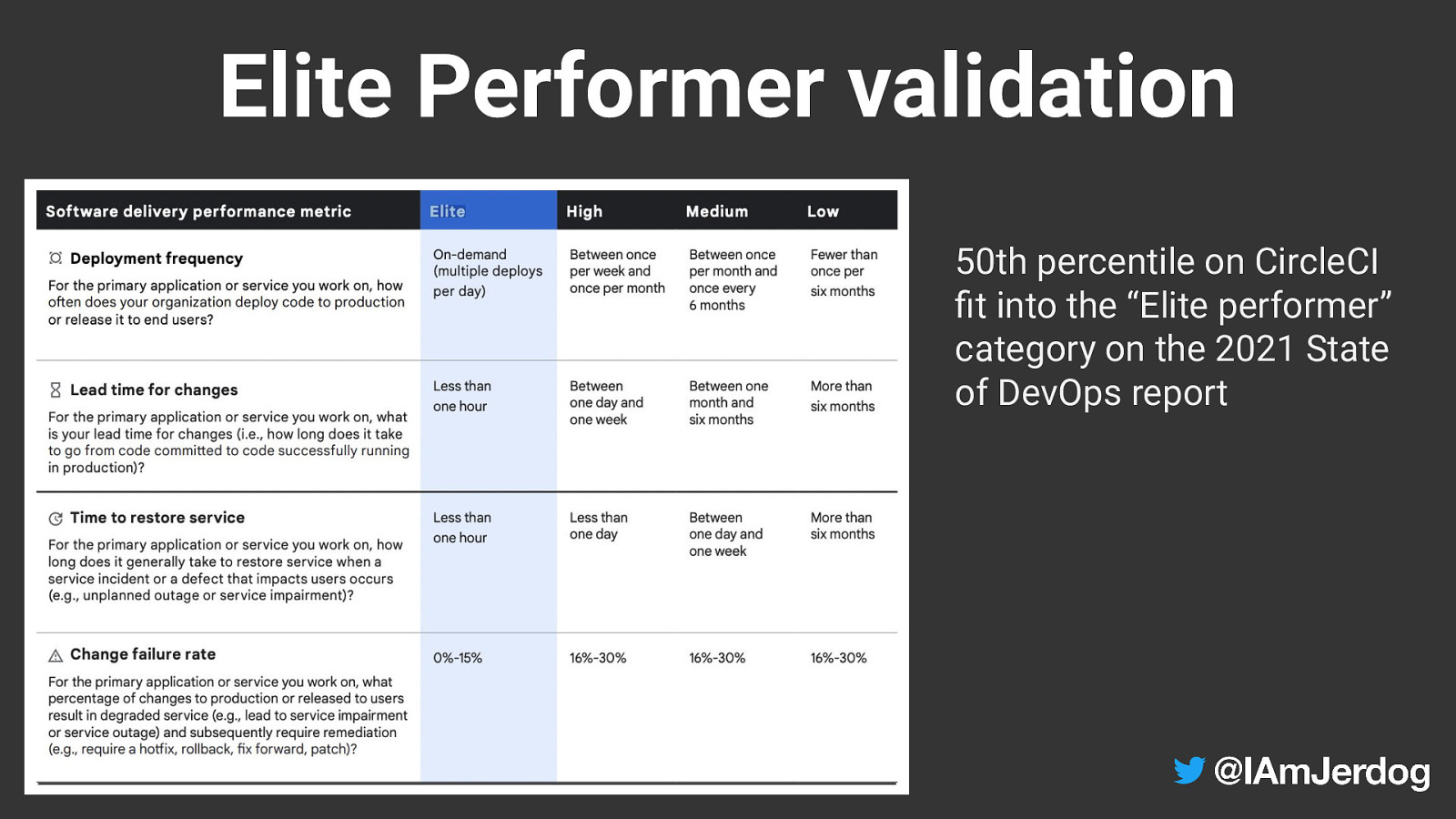
Elite Performer validation 50th percentile on CircleCI fit into the “Elite performer” category on the 2021 State of DevOps report
Slide 54

2020 Report Full 2022 Report https://circle.ci/ssd2020 https://circle.ci/ssd2022 54
Slide 55

Sony WF-1000XM4 Wireless Noise Canceling Earphones & Yamazaki 12 Years The winner will be notified by email on Sept 8, 2022 Single Malt Whiskey
Slide 56

Timeline.jerdog.me Thank you. For feedback and swag: circle.ci/jeremy IAmJerdog jerdog /in/jeremymeiss